![]()
EARLIER FEATURES
![]()
FEATURES CONTENTS
![]()
LATER FEATURES

|
|
|
|
| 8th February 2009 | WEB SITE COPIER - HTTRACK |
Brian Grainger
|
|
In this age of broadband and wi-fi connected Internet a lot of content providers assume that we are always connected and then make content only available for online viewing. Apart from being a huge snub to the many parts of the world that do not have broadband connections, there are many of us that, for security reasons, do not want to be always connected. This is the story of my search for a tool to download web sites, or parts of web sites, wholesale, to enable me to view the content offline. In passing, it also showed me that the perceived wisdom that Windows is better than Gnu/Linux , because it is so much easier to install anything on Windows, is not always true. THE PROBLEM Ever since I have been connected to the Internet I have wanted to take copies of material offline. I like to store it with the same folder structure as the original web site so that I know where it came from - it also makes it easier to link pages offline because I dont have to make many changes to the original links. The problem came to a head recently when the security on the server that holds the ICPUG web site was recently enhanced. I needed a new tool to upload the web pages, WinSCP. Unfortunately its documentation was held online in a wiki-like structure with no zipped up or pdf copy to download to view offline. There are, therefore, two prime requirements for the tool I need. First, it must allow the copying of web site information easily to a similar folder structure on the client PC. Second, the links need to be changed automatically so that the files can be browsed offline. THE HACKER SOLUTION Most people know that browsers hold a cache of the pages you have viewed online so that you may view them at leisure offline. They are seen as a security risk by some and a potential invasion of privacy by others. This is true but I found it was very handy for making offline copies of web site material! One of the (few) advantages of Internet Explorer (IE) is that the name of the files in the cache generally matched the original name on the web, perhaps with a distinguishing serialisation so that different pages with the same name can be cached in separate files. For example, there may be a few instances of index.htm in the cache. IE will store them as index(1).htm; index(2).htm; etc. Browsers such as Netscape would give the files obscure names such as 56gh587 so that they were totally useless for this task. My cheap and cheerful method of creating an offline copy of a website was therefore:
Because of the inherent insecurity of IE I knew that one day I would have to use a different browser and this technique would not work. I needed a tool to do the job for me. SEARCH FOR A TOOL Normally, I do not find it difficult to come up with the right search phrase for Google to quickly locate what I want. In this case I had a little difficulty. I did find something that looked as if it might do the job. I even downloaded it - but my doubts were such and the instructions for use were so daunting that I never looked at it! Stupid me - but more of that later. Serendipity then turned up. Very recently, Barry Kauler, the developer of Puppy Linux, wanted to copy offline the instructions to a new programming language and he asked the community how to do it. It was then that the community told me and Barry that the GNU Project already had a tool for just this job. It was called wget (for WWW Get). This tool was for Linux and, like most GNU tools, was written for usage at the command prompt. WGET AND DERIVATIVES My first step was to have a look at the man pages for wget. These tell you how to use it. I found that this was one powerful tool. There were all sorts of options to make it do just about everything you could think off with regard to transferring material from the WWW. Now, while I promote the use of free software I am not a masochist so I now decided to see if (a) there was a version of wget for Windows and (b) there was a version of wget that had a graphical user interface (GUI) as a front end. I now knew what to google for - wget for windows. I found that free software community had already created a version of wget compiled to run on Windows. This was still a command prompt tool so I looked further. Surprisingly, there were not many choices for wget with a GUI front end. There were two that I found. WinWget seemed to be a project that petered out in 2005 with some bugs on the bug list. The alternative was VisualWget, which was still active in 2008. VisualWget seemed to be a GUI front end that then used wget to do the business. No problem with that and the screen shots looked good. When I saw the software licence - the Microsoft Public Licence - I should have seen what was coming. This licence has apparently been approved by the Free Software Foundation as denoting free software. However they dont recommend that new software is distributed with this licence. I can see why. We have a perfectly adequate GPL - why do Microsoft have to create a similar licence with their name in it - divide and conquer? Having found the licence acceptable I then checked the system requirements. These were Windows and the .Net Framework 2.0. The .Net framework is a Microsoft supported way of rapid development of Windows apps. In the past Visual Basic was used and there was a visual basic runtime that had to be downloaded to enable the app to work. This was the modern equivalent where the .Net Framework runtime was needed to run the app. I went to get the .Net Framework thinking that it would simply be a file download. No such luck. The dependencies for .Net Framework were that you needed Windows XP SP2 (if using XP); the Windows Installer; IE 5 or later and 280MB of diskspace. All I want is to run an app - not have a new operating system. This is how Microsoft lock users into their products. VisualWget may be free software, but you need non-free stuff to get/run it. Thank you and good night. THE SOLUTION - HTTRACK
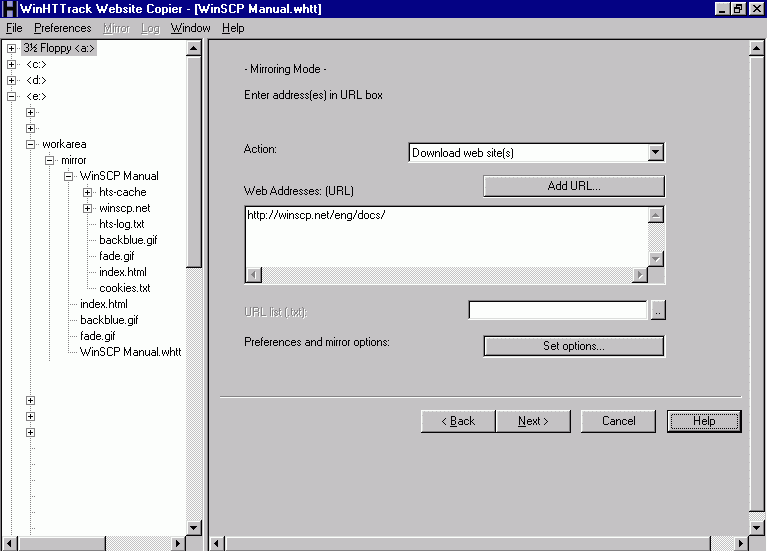
Fortunately the Puppy Linux community did not just recommend wget. They also mentioned the tool HTTrack. The Windows version of this program, WinHTTrack, was the original program I had downloaded when I first started looking for a tool. It was time to look at this tool in greater detail. It certainly did not have any licence problems because it is distributed under the GNU GPL licence. When you look at the web site for WinHTTrack you can view the documentation. It is extensive. However, it is full of warnings about using the download options carefully to make sure you don't try and download too much, (like the whole internet), or upset your ISP or the target web site you are trying to copy. It was this that originally put me off using the tool. I was too scared I was going to do something wrong! Of course, these warnings apply whatever tool you use but I was concerned that WinHTTrack would not help me to avoid problems. Now that I had a real need for WinHTTrack I was prepared to go ahead and accept the risk. I needn't have worried. When you open WinHTTrack you are greeted with a folder tree for your computer on the left side of the screen and a welcome screen inviting you to click the Next button to start a new project or resume a previous project. The next screen asks you to give the project a name, (or select a previous project from the drop down list), and define the base path, the folder where the download would be stored. Clicking the Next button leads you to the main screen, where you define the URL(s) where the download is to come from and the download options. The latter are extensive so I just went with the defaults. Clicking the Next button at this point will, provided you are connected to the internet, begin the download. It may take some time! When I downloaded the manual from the WinSCP site it seemed to take forever and seemed to be duplicating pages downloaded. When I looked afterwards I found this to be true. There were up to four copies of each web page, all different. However, I think this was related to the fact that the WinSCP manual is created on a wiki so that anybody can edit it. Looking at a standard html format page shows links to pages in text format and wiki format and it is these pages that WinHTTrack had downloaded as well. Whatever, it did a very good job. When I clicked on the index.html page in the folder given by the project name I got the opening page of the WinSCP manual and I found I could click through to the other pages just as if I was online. WinHTTrack had proved itself a very valuable tool. WINHTTRACK NOTES The default options I was so worried about seemed to be very sensible. The program downloaded html pages, stylesheets and javascript as well as common image formats but did not download video files, for example. The download speed setting was limited to a sensible value. It did make use of multiple connections. Most importantly it restricted itself to downloading pages within the desired site and did not spider off to other sites that may have been referenced. It also had filters against pages from doubleclick being downloaded. Here is the wildcard options in the configuration file so you can see what I mean: WildCardFilters=+*.png +*.gif +*.jpg +*.css +*.js -ad.doubleclick.net/* -mime:application/foobar The html formatted pages that are downloaded have comments within them that identify that the pages have been downloaded by HTTrack and where they have come from. WinHTTrack creates a folder for each project name located within the base path specified. The project name folder includes some files created by WinHTTrack and also a folder hts-cache which includes other files created by WinHTTrack that are used for updating the mirror at a later date. Finally there is a folder for the url mirrored and below this is the structure of the mirrored website. There is an index.html file within the project name folder which hooks into the start point of the mirror. The help file within the WinHTTrack application is a little odd in that its start page seems to be at the step by step description. Maybe this is a function of what has been viewed previously in the help. However, be sure to click the Home button on the help toolbar to see all the help available, including the complete documentation from the web site. The WinHTTrack program seems to come with the source files for both the Windows and Linux version of the program. Very useful if you want to make some changes. CONCLUSION I was wrong to be wary of WinHTTrack when I first looked at it. This program seems to be the definitive GUI tool for downloading web sites for offline browsing. It is free software - in both senses. It comes for Linux or Windows. It has extensive help documentation. It does the job! Xavier Roche and the team can be justly proud of their creation. |
|
|
|
|
|
|
|
|
|
|